

400-123-4567
站内公告:
2024-03-12 12:09:29
Geatpy是一个高性能实用型进化算法工具箱,可用于求解单目标优化、多目标优化、复杂约束优化、组合优化、混合编码进化优化等。内部封装了多种算法,包括遗传算法,差分进化算法,群粒子算法,模拟退火算法等。
Geatpy文档:http://geatpy.com/index.php/%e6%80%bb%e8%a7%88/
安装:
Geatpy2整体上看由工具箱内核函数(内核层)和面向对象进化算法框架(框架层)两部分组成。其中面向对象进化算法框架主要有四个大类:Problem问题类、Algorithm算法模板类、Population种群类和PsyPopulation多染色体种群类。UML图如下所示:

这些算法模板通过调用Geatpy 工具箱提供的进化算法库函数实现对种群的进化操作,同时记录进化过程中的相关信息,其基本层次结构如下图:
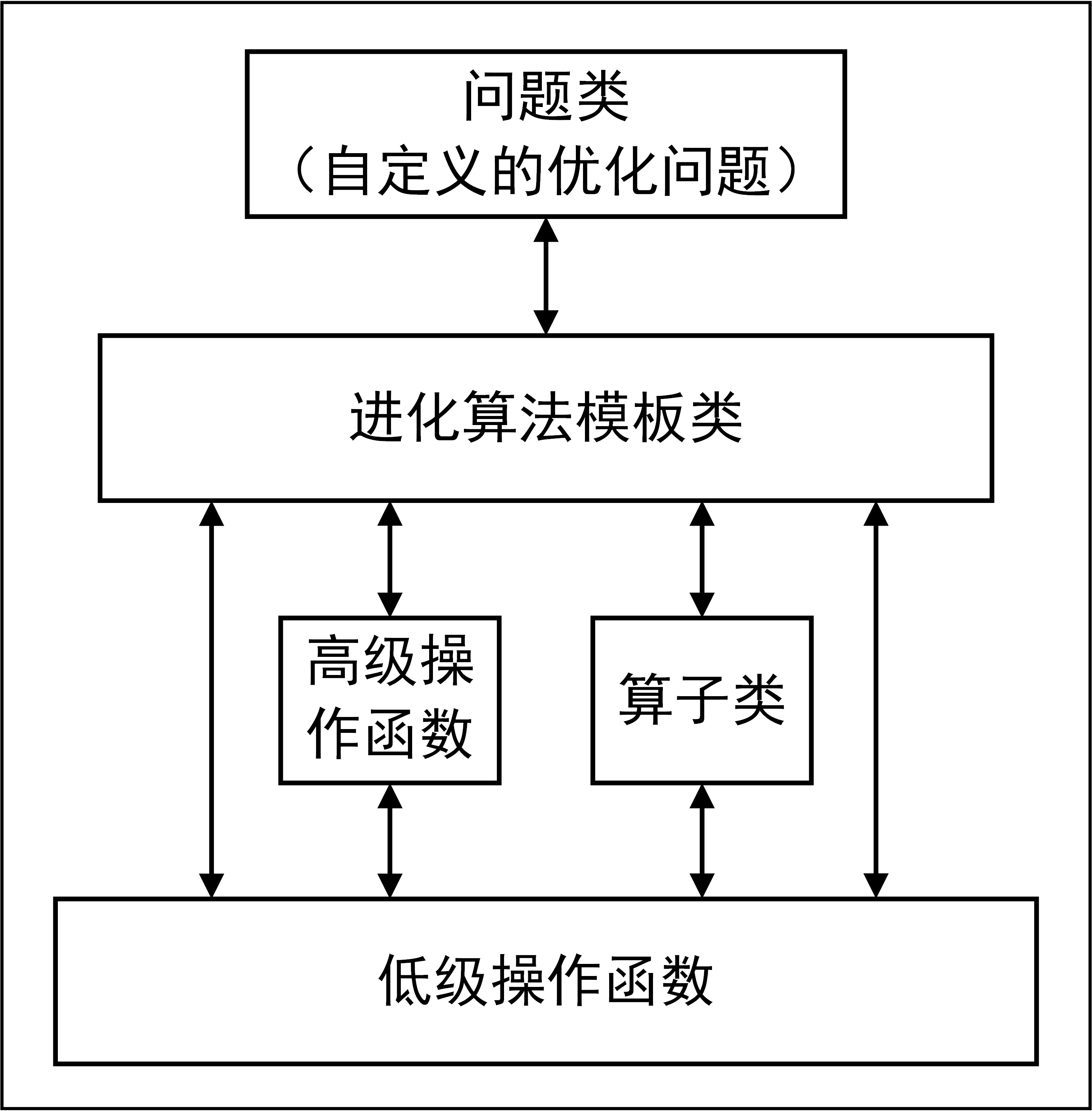
其中“算子类”是Geatpy2.2.2版本之后增加的特性,通过实例化算子类来调用低级操作函数,可以利用面向对象编程的优势使得对传入低级操作函数的一些参数的修改变得更加方便。目前内置的“算子类”有“重组算子类”和“变异算子类”。用户可以绕开对底层的低级操作函数的修改而直接通过新增“算子类”来实现新的算子例如自适应的重组、变异算子等。
参数说明:
遗传算法(Genetic Algorithm)中的基因,并不一定真实地反映了待求解问题的本质,因此各个基因之间未必就相互独立,如果只是简单地进行杂交,很可能把较好的组合给破坏了,这样就没有达到累积较好基因的目的,反而把原本很好的基因给破坏了。精英保留策略可以避免最优个体不会因为杂交操作而被破坏。
精英保留策略:是针对遗传算法提出来的。对遗传算法来说,能否收敛到全局最优解是其首要问题。De Jong提出该策略的思想是,把群体在进化过程中迄今出现的最好个体(称为精英个体elitist)不进行配对交叉而直接复制到下一代中。 这种选择操作又称为复制(copy)。
标准遗传算法不能全局收敛的主要原因:
(1) 采用比例选择法,由于存在统计误差,依据产生的随机数进行选择,有可能会出现不正确地反映个体适应度的选择,可能导致适应度高的个体也被淘汰掉;
(2) 交叉、变异算子可能会破坏掉个体中所隐含的高阶(high-order)、长距(length)、高平均适应度模式(schema),可能导致当前群体中的最优个体在下一代群体中发生丢失,而且这种最优个体丢失现象会周而复始的出现在进化过程中。
De Jong对精英保留策略方法作了如下定义:
设到第t代时,群体中 a(t)为最优个体。又设A(t+1)为新一代群体,若A(t+1)中不存在比a(t)优的个体,则把a(t)加入到A(t+1)中作为A(t+1)的第n+1个个体,这里n为群体的大小。
为了保持群体的规模不变,如果精英个体被加入到新一代群体中,则将新一代群体中适应度值最差的个体就淘汰掉。
精英个体是种群进化到当前为止遗传算法搜索到的适应度值最高的个体,它具有最好的基因结构和优良特性。采用精英保留的优点是,遗传算法在进化过程中,迄今出现的最优个体不会被选择、交叉和变异操作所丢失和破坏。精英保留策略对改进标准遗传算法的全局收敛能力产生了重大作用,Rudolph已经从理论上证明了 具有精英保留的标准遗传算法是全局收敛的。
问题1:

量的范围。
增强精英保留策略的遗传算法SEGA步骤:
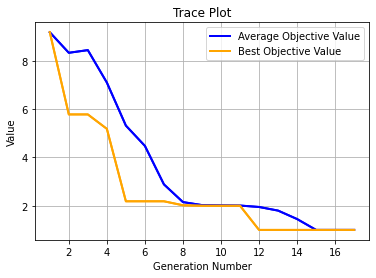
用Geatpy工具中SEGA算法解决问题1:
输出为:
1.方法一
说明:
这里的目标函数定义成aimFunc,而不是evalVars。
aimFunc(pop)传入的是一个种群对象pop。
pop.Phen是种群的表现型矩阵,等价于决策变量矩阵。它是Numpy ndarray的二维数组,每一行表示一组决策变量值。
pop.ObjV是种群的目标函数值矩阵。它是Numpy ndarray的二维数组,每一行表示一组目标函数值。
pop.CV是种群的违反约束程度矩阵。它是Numpy ndarray的二维数组,每一行表示一组违反约束程度值。
2.方法二
说明:
这里的目标函数定义成evalVars,而不是aimFunc。
区别:
aimFunc(pop)传入的是一个种群对象。
而evalVars(Vars)传入的是一个Numpy ndarray二维数组。其每一行的所有元素表示一组决策变量。
函数evalVars可以有一个或两个返回值。第一个返回值表示目标函数值矩阵;第二个返回值表示违反约束程度矩阵。
如果没有约束,则只需返回一个返回值即可。因此用法为:
ObjV = evalVars(Vars) 或 ObjV, CV = evalVars(Vars)
3.方法三
说明:
与上面不同的是本案例采用循环计算每个个体的目标函数值和违反约束程度值。
4.方法四
说明:
本案例通过装饰器single标记目标函数evalVars,使得目标函数只传入一组决策变量。
此时目标函数只需计算这组变量对应的目标函数值以及违反约束程度值。
用法:
ObjV = evalVars(Vars) – 若无约束 或 ObjV, CV = evalVars(Vars) – 若有约束
注意:
加了装饰器single后,evalVars的传入参数Vars不再是Numpy ndarray二维数组,而是Numpy ndarray一维数组。
在设置返回值时:
返回值ObjV可以赋值为一个Numpy ndarray一维数组,也可以是一个标量(当只有一个优化目标时)。
返回值CV可以赋值为一个Numpy ndarray一维数组,也可以是一个标量(当只有一个优化目标时)。
值得注意的是:
通过调用evalVars(Vars)得到的返回值会被single装饰器修正为Numpy ndarray二维数组。
即ObjV = evalVars(Vars)得到的ObjV或:ObjV, CV = evalVars(Vars)得到的ObjV和CV,均为Numpy ndarray二维数组。
NSGA2多目标遗传算法介绍:https://blog.csdn.net/q15615725386/article/details/119521206
NSGA算法是以遗传算法为基础并基于Pareto最优概念得到的。NSGA算法与标准遗传算法的主要区别是其在进行选择操作之前对个体进行了快速非支配排序,增大了优秀个体被保留的概率,而选择、交叉、变异等操作与基本遗传算法无异。
(1)算法计算量大。NSGA算法的计算复杂度与种群数量N、目标函数个数m的关系为T = O(mN3),当种群规模较大、目标函数较多时所耗时间较长。
(2)没有应用精英策略。未通过精英策略提高优秀个体的保留概率,因而无法加快程序的执行速度。
(3)需要人为地指定共享半径R,对于经验的要求非常高。
(1)NSGA-II算法使用了快速非支配排序法,将算法的计算复杂度由O(mN3)降到了O(mN2),使得算法的计算时间大大减少。
(2)采用了精英保留策略,将父代个体与子代个体合并后进行非支配排序,使得搜索空间变大,生成下一代父代种群时按顺序将优先级较高的个体选入,并在同级个体中采用拥挤度进行选择(排除较差的个体),保证了优秀个体能够有更大的概率被保留。
(3)用拥挤度的方法代替了需指定共享半径的适应度共享策略,并作为在同级个体中选择优秀个体的标准,保证了种群中个体的多样性,有利于个体能够在整个区间内进行选择、交叉和变异。
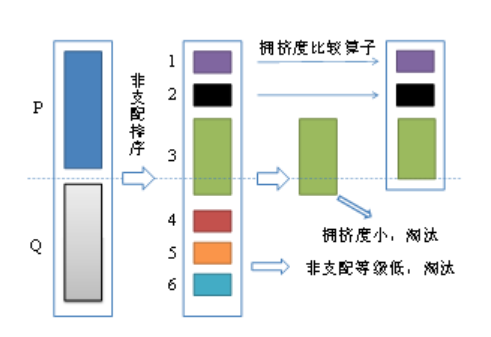
(1)将父代种群和子代种群合并形成新的种群。之后对新种群进行非支配排序,本例中将种群分成了6个Pareto等级。
(2)进行新的父代的生成工作,先将Pareto等级为1的非支配个体放入新的父代集合当中,之后将Pareto等级为2的个体放入新的父代种群中,以此类推。
(3)若等级为k的个体全部放入新的父代集合中后,集合中个体的数量小于n,而等级为k+1的个体全部放入新的父代集合中后,集合中的个体数量大于n,则对第k+1等级的全部个体计算拥挤度并将所有个体按拥挤度进行降序排列,之后将等级大于k+1的个体全部淘汰。本例中可以看出k为2,所以对Pareto等级为3的个体计算拥挤度并按其进行降序排序,等级为4~6的个体全部淘汰。
(4) 将等级k+1中的个体按步骤2中排好的顺序逐个放入新的父代集合中,直到父代集合中的个体数量等于n,剩余的个体被淘汰。
问题2:
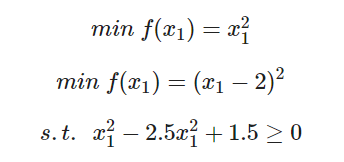
#用NSGA2算法来解决双目标优化问题步骤
用Geatpy工具中NSGA2算法解决问题2:
输出为:
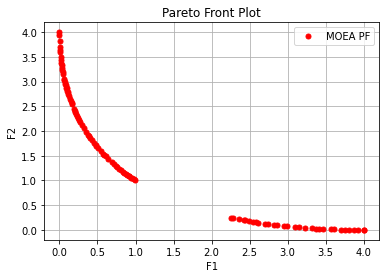
Execution time: 0.10509157180786133 s
Evaluation number: 20000
The number of non-dominated solutions is: 100
hv: 0.83201
spacing: 0.02100
ZDT1、DTLZ1(DTLZ1—7)、WFG1,等等。以DTLZ1为例,可以通过ea.benchmarks.DTLZ1()直接实例化DTLZ1问题对象。用NSGA3算法求解DTLZ1的代码如下:
Geatpy2.7.0把已实现的测试问题归档进了benchmarks文件夹中,所以可以直接修改benchmarks后面的函数来测试某个问题
输出为:
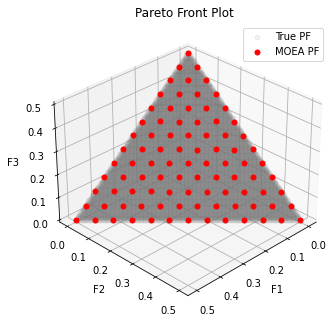
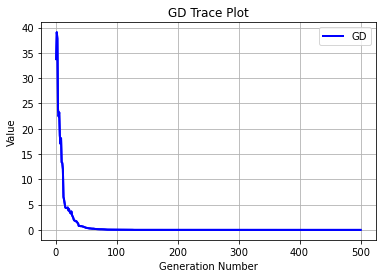
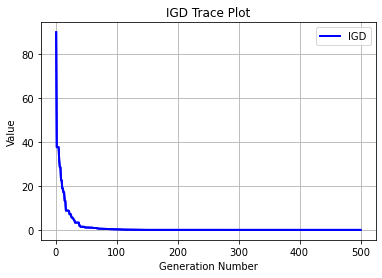
Execution time: 0.5562167167663574 s
Evaluation number: 45500
The number of non-dominated solutions is: 91
gd: 0.00020
igd: 0.02062
hv: 0.84156
spacing: 0.00028
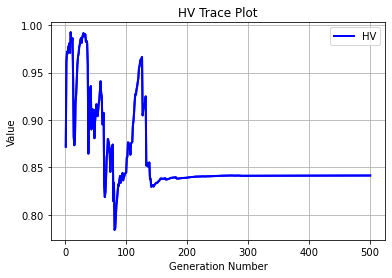
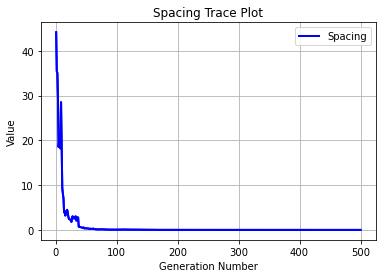
Geatpy工具:




