

400-123-4567
站内公告:
2024-04-15 12:39:34
灰狼算法(GWO)非自动化的参数调整和缺乏系统的停止标准,通常会导致计算资源的低效使用。本文介绍一个改进版的灰狼优化器(GWO),名为自适应的GWO(AGWO),它通过在优化过程中根据候选方案的适配性自适应调整探索/开发参数来解决这些问题。
在优化过程中,通过基于候选解决方案的适配性历史,自适应地调整探索/开发参数来解决这些问题。通过根据优化过程中适配度提高的重要性来控制停止标准,AGWO解决了这些问题,可以在最短的时间内自动收敛到一个足够好的最优方案。
GWO算法的一个主要局限性是,它要求我们选择一些最大的迭代值。要求我们选择一些最大的迭代值T,这影响了操作的计算时间。如果这个参数被选得太小,我们就会过早地收敛到一个不满意的点上这可能离目标函数的真正最小值很远。另一方面,增加这个参数来确保收敛到一个假定的好的点可能会导致计算时间的浪费,而对最终的质量没有明显的改善。
灰狼算法的改进角度有三种,一是改参数,增加一些context,而是与其他算法杂交,取他人之长,三是设计算子,如下图所示:
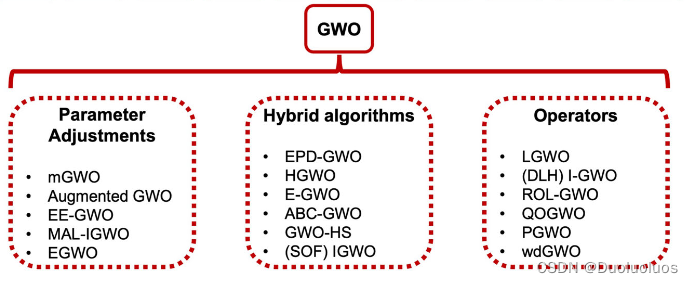 这些改进措施有缺陷:
这些改进措施有缺陷:
1、没有分析目标函数,一个未知的目标函数有一个未知的复杂性,未知的目标函数有一个未知的复杂性。而所需时间在很大程度上取决于目标函数。
2、这些算法都不能根据目标函数自动调整收敛参数,仍然需要事先输入最大迭代次数。
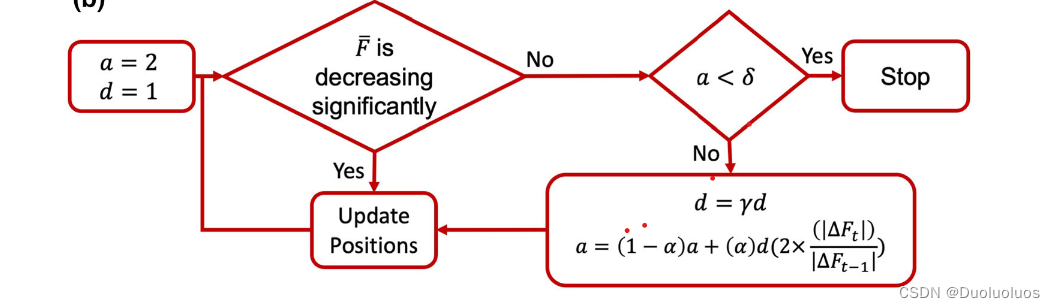
AGWO提出了阻尼参数的概念,即减少系数
λ
\lambda
λ,它可以减少探索率。这种参数的减少类似于基于梯度的方法中常用的学习率衰减。AGWO令历史的窗口平均适应度
F
m
o
v
a
v
g
F_{movavg}
Fmovavg?。
和其他自适应GWO算法一样,AGWO也是修改
a
a
a,当且仅当
F
ˉ
≥
F
m
o
v
a
v
g
?
?
\bar{F} \ge F_{movavg}-\epsilon
Fˉ≥Fmovavg???,
a
a
a得以衰减,即
a
=
γ
a
a=\gamma a
a=γa。否则更新狼群参数。
由此提出了宕机准则: a < σ a<\sigma a<σ是停止迭代。
AGWO类别深度学习里的梯度优化器Adam,利用适应度函数的梯度来选取
a
a
a,即:
a
=
(
1
?
α
)
a
+
(
α
)
d
(
2
×
(
∣
Δ
F
t
∣
)
(
∣
Δ
F
t
?
1
∣
)
)
a=(1-\alpha)a+(\alpha)d(2 imes \frac{(|\Delta F_t|)}{(|\Delta F_{t-1}|)})
a=(1?α)a+(α)d(2×(∣ΔFt?1?∣)(∣ΔFt?∣)?),
a
a
a随
d
d
d的衰减而衰减。
详细代码见这个github仓库,这里分析AGWO代码:




